Jekyll2024-09-04T13:34:34-04:00https://dando18.github.io/feed.xmlDaniel NicholsDaniel NicholsStocking the Bar2023-02-02T00:00:00-05:002023-02-02T00:00:00-05:00https://dando18.github.io/posts/2023/02/02/barExperimenting with cocktails and the myriads of flavors and presentations
can be a delightful culinary avocation.
However, stocking a bar is expensive.
Different mixing alcohols typically range from 10-50 USD and you also need a
swarm of other syrups, garnishes, and toppers.
Even with a reasonable selection of bottles one can still find themselves with
a lackluster number of cocktails that they can make.
After going through this morose experience myself I began to wonder what an
ideal set of cocktail ingredients would be.
As it turns out this problem can be solved (sort of) with some
old fashioned computer science.
Finding the Right Ingredients
So how do we go about finding an optimally stocked bar?
First, we need to define what optimal is.
But before I lay out the objective, let us define a couple of terms.
Let \(R\) and \(I\) be the set of
all recipes and ingredients, respectively. We will say a set of ingredients
\(A \subseteq I\) satisfies a recipe \(r \in R\) if \(r\) can be made
using the ingredients in \(A\).
The most interesting problem (at least to me) is given a positive
integer \(k\) can we find the set of ingredients of size at most \(k\)
that satisfy the largest number of recipes.
I.e. if we are only allowed \(k\) ingredients, how do we select these
ingredients such that we can make the most recipes with them.
This can be notated as:
Here \(\mathbb{1}_{\{A\ \textrm{satisfies}\ r\}}\) is an indicator function
that is \(1\) when the ingredients \(A\) satisfies the recipes \(r\) and
\(0\) otherwise.
A Brute-Force Solution
A more algorithmic friendly way to write our problem
is by considering the related problem of what recipes do not need
a list of ingredients. In this sense let \(R_i \subseteq R\) be
the set of recipes that do not use ingredient \(i\in I\). The intersection of
these sets, for instance \(R_i \cap R_j \cap R_k\), represents the set of all
recipes that do not use ingredients \(i, j,\) and \(k\). Now finding the largest
intersection of at most \(\lvert I \rvert - k\) of these subsets will give
the largest set of recipes that can be made with \(k\) ingredients.
The brute-force algorithm for this can be expressed rather simply.
# create list of subsets R_i for each ingredient i; R_i is all recipes that can be made without i
subsets=set(frozenset(rforrinrecipesifnotr.uses_ingredient(i))foriinall_ingredients)max_subsets=max(combinations(subsets,len(subsets)-k),key=lambdas:len(frozenset.intersection(*s)))
This algorithm is equivalent to the minimum \(k\)-union problem and has been
proven to be NP-Hard [1].
In the worst case it will iterate over
\(\binom{\lvert I\rvert}{\lvert I\rvert-k}\) combinations of sets and compute
their intersection size.
While the number of recipes \(\lvert R\rvert\) impacts the duration to compute
the set intersections, this complexity is largely dominated by the
\(\lvert I\rvert !\) factorial term. Thus, it is necessary to keep this term
small so that the brute-force algorithm can finish in a reasonable amount of
time. Fortunately, the number of unique ingredients likely lies between 20 and
100 for a reasonable list of recipes making it easy to keep small.
We also benefit from the fact that this algorithm is likely being run
with very small values of \(k\) as that is of most interest.
We can further reduce the number of ingredients, \(\lvert I \rvert\), with a
couple of data set augmentations.
First, we can remove unnecessary ingredients from recipes. This includes any
items we are likely to already possess, such as ice, water, salt, sugar, etc.
We can also remove garnishes from the recipes if we just care about the main
drink. Additionally, we can make substitutes where applicable so as to reduce
the total number of unique ingredients. For example, we may replace instances of
Rye Whiskey or Bourbon with just Whiskey.
These three optimizations can meaningfully reduce the total search space for
the brute-force algorithm.
Other Algorithms
Using the reduced ingredients set from the brute-force algorithm I have also
implemented several other algorithms and heuristics for comparison.
These are detailed below.
k Most Common Ingredients
Here we compute the number of occurrences of each ingredient across all recipes
and take the \(k\) most common.
This could potentially yield the optimal solution or the worst case of 0
total recipes.
It has the benefit of a good time complexity: counting is \(O(\lvert I\rvert)\)
and finding the \(k\) most common is \(O(\lvert I\rvert\log k)\) with a
heap queue. For a small fixed \(k\) this is linear in \(\lvert I\rvert\).
Max Recipe Degree
Construct a graph \(\mathcal{G}_R=(V,E)\) where \(V=R\) and \((r_i, r_j)\in E\)
iff \(r_i\) and \(r_j\) share an ingredient. Also constructed a weighted version
of \(\mathcal{G}_R\) where \(w_{r_i,r_j}\) is equal to the number of shared
ingredients between \(r_i\) and \(r_j\).
Now select the max degree vertex \(v^* = \max_{v\in V}\deg v\) and remove it
from the graph.
Update a set with the ingredients of \(v^*\).
Continue this process until the set being built has size \(\ge k\) or the
graph is empty.
Select the built set as the final list of ingredients.
The time complexity is dominated by the graph construction which is
roughly \(O(\lvert R\rvert^2)\).
Max Ingredient Degree
Similar to above construct a graph \(\mathcal{G}_I=(V,E)\) where \(V=I\) and
\((i_m, i_n)\in E\) iff \(i_m\) and \(i_n\) are in a recipe together.
The weight of the edge \(w_{i_m,i_n}\) is the total number of recipes that
have both \(i_m\) and \(i_n\).
Select and remove the highest degree vertex \(v^*=\max_{v\in V}\deg v\).
Do this \(k\) times or until the graph is empty.
The \(k\) removed vertices are the final selected set of ingredients.
Greedy
Instead of fixing the ingredients this algorithm fixes the number of recipes to
\(k\) and tries to find the smallest number of ingredients that satisfy at
least \(k\) recipes.
Let \(A=\{\}\) be an empty set of recipes.
Pick a recipe \(r^*\in R\) thats ingredients minimize the union of \(A\) and
the ingredients of \(r^*\), i.e. \(r^* = \min_{r\in R}\lvert A \cup r\rvert\).
Remove \(r^*\) from \(R\) and update \(A\) such that \(A=A\cup r^*\).
Repeat this process \(k\) times.
This guarantees that the ingredients in \(A\) satisfy at least \(k\) recipes.
At each step we take the locally optimal solution making this a greedy
algorithm.
We end up computing \(O(k\lvert R\rvert)\) unions making this a fairly fast
heuristic algorithm.
Random Sampling
This is just to serve as a benchmark.
We take \(M\) random subsets of size \(k\) from \(I\).
The one that satisfies the most recipes is selected.
When testing I use an alternate method where I continue sampling until a
certain duration has passed (1 second).
Once that duration has passed the best subset found during sampling is selected.
Results
I implemented all of the above in Python to compare their results and runtimes.
This code can be found here.
For input I used a hand-compiled set of 25 cocktail recipes found from
various internet sites.
Before running the algorithms the garnishes are filtered out and substitutions
for common ingredients are made as described in the brute-force algorithm.
It should be noted that the brute-force exhaustive algorithm was only run
up to \(k=10\) due to time limits. Additionally, due to the use of sets and
Python 3’s non-deterministic hash functions the final list of ingredients found
by each algorithm is non-deterministic (however, its size is).
The first figure, depicted below, shows the number of recipes satisfied
(\(y\)-axis) by the returned list of ingredients (\(x\)-axis).
Each line represents a different algorithm.
We see that greedy performs very near the brute-force solution (note:
exhaustive cuts off after \(k=10\) due to time limits).
The rest all perform similarly with result sizes about 3-4 lower than the
optimal.
Furthermore, the next figure highlights the runtime of each algorithm.
Note the \(y\)-axis is log scale 10.
As expected we see an exponential blow up in runtime for the brute-force
solution.
This algorithm, while exact, is infeasible for realistically sized data sets.
Combined with the above results we can conclude that the greedy algorithm
is the best in terms of result to performance trade-off.
The Best Ingredients
The numbers are indeed interesting, but what is the best subset of ingredients?
This what we initially set out for after all.
Running the brute-force algorithm with \(k=10\) on
my small recipe data set
we get the following list of ingredients.
These, plus common household ingredients and garnishes, can be used to make
the following 11 recipes.
Negroni, Hot Toddy, Jack and Coke, Boulevardier, Dry Martini, Gin Tonic,
Boilermaker, Manhattan, Old Fashioned, Irish Coffee, Whiskey Neat
Note that these results are severely impacted by the data set used.
For example I could artificially inflate the result by adding recipes to my
list that are just combinations of these 10 ingredients.
Thus, the scale of these numbers, 10 ingredients and 11 recipes, is not as
interesting, but rather their optimality for this particular \(R\) and \(I\).
In this case, since we used the brute-force algorithm, we can conclude that
this is the optimal solution for our particular list of recipes.
For \(k=5\) the brute force algorithm gives the following.
For larger \(\lvert I\rvert\) and/or \(k\) we will need to switch to the
greedy heuristic algorithm.
However, we have previously demonstrated that this algorithm is a good
candidate for finding good ingredient sets.
]]>Daniel NicholsML Madness2022-03-16T00:00:00-04:002022-03-16T00:00:00-04:00https://dando18.github.io/posts/2022/03/16/ml-madnessMarch Madness brings about spirited competition amongst friends and family
to see who can pick the better basketball tournament bracket.
Some pick theirs randomly, some pick by favorite mascot, while others try to use in-depth
basketball knowledge to get the edge.
At the end of the day, however, there is one winner and many losers.
To add to the competitive atmosphere I decided to pit a bunch of machine learning algorithms
against each other to see which could generate the better bracket.
In this post I detail a methodology for collecting college basketball data,
training ML models to predict game outcomes, and filling out brackets for
tournaments to come.
The entirety of the code used can be found here.
Since I am posting this before the tournament starts I will come back in April
and revisit how the models performed.
There are a number of college basketball datasets already available online, which
makes the data collection straightforward.
This dataset contains NCAA tournament
results dating back to 1985 (when the tournament was expanded to 64 teams).
Additionally, this site displays end-of-season
statistics for every team from 2008 to 2022.
Both of the above datasets can be directly downloaded as CSVs.
I do this in Python and left join the two CSVs along year and team.
Predicting Outcomes
The ML problem is set up to predict the winner of a game based on information about the two teams playing.
In this setup the model is given
and predicts a 1 if \(\textrm{team }1\) wins and a 0 if \(\textrm{team }2\) wins.
The first 3 features and the output label are all available from the tournament results dataset.
The rest are taken from the end-of-season statistics dataset.
This contains the following statistics for each team, each year:
Conference, Games Played, Games Won, Adjusted Offensive Efficiency, Adjusted Defensive Efficiency,
Power Rating, Effective Field Goal Percentage Shot, Effective Field Goal Percentage Allowed,
Turnover Rate, Steal Rate, Offensive Rebound Rate, Offensive Rebound Rate Allowed,
Free Throw Rate, Free Throw Rate Allowed, 2Pt %, 2Pt % Allowed, 3Pt %,
3Pt % Allowed, and Adjusted Tempo.
See the columns on the dataset’s website
for more information on what these mean.
Each of these stats are taken from both teams and inputted into the model.
Each of these columns are normalized in the final dataset.
To rapidly try out many different models I used those already available in sklearn.
A subset of the classification models
were fit on the above training data.
Grid search was used to find good hyperparameters for each model.
Then 5-fold cross-validation was used to score each model based on average accuracy.
Results
After tuning and fitting each model the best accuracy was achieved with the
Support Vector Machine (SVM) classifier at 72%.
The accuracies for each model are shown below.
72% is not great, but it is still better than the random guessing model.
Also given that we are just using a couple end-of-season statistics this seems like
a reasonable accuracy.
Better predictions would probably require more sophisticated input data.
Brackets
I simulated the 2022 tournament using each of the trained models.
I inputted each generated bracket into ESPN’s bracket challenge and put screenshots of the
resulting brackets below.
Also included is my personal bracket, which will serve as a comparison point to
the ML generated brackets.
Here are the scores of each bracket at the end of the tournament.
The second plot shows the percentile of the bracket within the national pool.
Random Forest classifier wins!
With a score of 780 it finished in the 87.2 percentile nationwide.
Interestingly this model did not have the highest testing accuracy.
The model with the highest accuracy on the training data, the SVM, came in
2nd overall landing in the 75.9 percentile.
Ultimately none of the brackets picked Kansas as the winner.
The Random Forest had Kansas in the championship game, which is why it
ended up scoring the highest.
Additionally, none of them predicted the magic Saint Peter’s run, albeit,
neither did most of the country.
Conclusion and Points of Improvement
The results were decent and go to show the amount of unpredictability in the
NCAA tournament.
However, they are very informative and give me some ideas for how to improve by
next March.
First, all of the brackets scored very low due to performing poor in the later
rounds.
There were lots of upsets early on, but traditionally good teams ended up
surviving into the final games.
This hurt the final score of most of the models, since games are weighted by
round such that each round of the tournament contributes equally to the final
tally.
Obviously predicting later games is difficult, but I can try to bias the
models towards them.
One trivial way to do this is to train to optimize bracket score instead of
game outcome prediction rate.
Second, there are many important statistics left out of my model.
For instance the KenPom scores could also be informative
inputs into the model.
Next year I will scrape more statistics to use as inputs into the model.
Related to this is historical information about the teams.
This year we saw all “blue-bloods” in the final four.
Historically good teams, despite their statistics, are still favored to make
it far in the tournament.
Finally, time series data can be included to help account for momentum.
Sometimes teams get “hot” at the end of their season and come into the
tournament with considerable momentum.
Their early season statistics may skew the aggregate statistics enough to
confuse the model.
Using time series models such as LSTM neural networks may ameliorate final
results.
Altogether, the experiment was fun to follow along throughout March and
now I have an extremely “scientific” means to validate my future ML model
selections.
Next year I will be back with some hopefully improved models.
]]>Daniel NicholsWordle: Finding the Right Words to Say2022-01-24T00:00:00-05:002022-01-24T00:00:00-05:00https://dando18.github.io/posts/2022/01/24/wordleThe Wordle trend has grabbed
the attention of an omicron laden society stumbling their way into a new year.
It is a fun word game by Josh Wardle where each day a new word is
released for people to guess.
The daily release schedule, minified design, and simple game mechanics
have made the game a viral hit.
On being shown the game the first time I was naturally curious as to what the
best guessing strategy is.
So I did a bit of thinking and some research to arrive at a couple good
solutions.
These are outlined and compared below alongside some other interesting
information about the game.
The objective of the game is to guess a secret 5 letter word.
Upon guessing a word the player is informed for each letter whether it is
correct, misplaced, or incorrect.
Correct means that the corresponding letter is in the secret word in the same
position, while incorrect means that letter is not in the secret word at all.
Misplaced means the letter is in the secret word at least once, but is in the
wrong position.
For example, if the secret word is “dance” and the player guesses “later”, then
the result would be INCORRECT, CORRECT, INCORRECT, MISPLACED, INCORRECT.
The player wins if they can get 5 correct letters (guess the word) in 6
turns, otherwise they lose the game.
Nostalgic board game players will recall that this is the same as the
popular 70s game
Mastermind using letters
instead of colored pegs.
In Mastermind one player chooses a secret code of 4 colored pegs with 6
possible colors.
Following the same rules outlined above the other player tries to guess the
secret code.
Mastermind itself is actually an adaptation of an older game called
Bulls and Cows.
Some Interesting Properties
If we assume that all \(26^{5}\) letter combinations are possible codewords,
then Wordle is equivalent to Mastermind with 26 colors and length 5 codes.
It has been shown that Mastermind is
NP-complete
in the length of the code
[1].
Best strategies?
When selecting a strategy our main concerns are the maximum number of guesses
and the likelihood of winning.
If the maximum number of possible guesses is above 6, then it is possible for
that strategy to lose.
When it is possible for a strategy to lose, then we care about how often it
will win.
The best strategy would never lose, but if that is not feasible, then it is
desirable to find the one which wins most often.
With these objectives in mind there are several ways to approach choosing the
next guess.
You can try to find the most likely next word, the word which will remove the
most possibilities from the word list, etc…
I describe some here which I found to be quite successful.
In each I make the assumption that you know the full list of possible words
\(\mathcal{W}\).
This is a reasonable assumption, since in the worst case you can use all 5
letter words in the english dictionary as \(\mathcal{W}\).
Random Guessing
The most obvious strategy and a control for the others is random selection.
Each turn the player randomly selects a word from \(\mathcal{W}\) as their
guess.
If the player randomly selects without replacement and does not remove
impossible words after each guess, then the expected number of guesses is
\(\lvert\mathcal{W}\rvert /2\) and the maximum is \(\lvert\mathcal{W}\rvert\).
This is a fairly poor strategy as you have a \(6/ \lvert\mathcal{W}\rvert\)
chance of winning.
However, it can be greatly improved by removing impossible words from
\(\mathcal{W}\) after each guess as this drastically reduces the number of
words to select from.
This is also similar to how people play the game.
They do not continue guessing words they know will not work.
Minimax
Normally in game theory a random strategy can be improved by using a
minimax selection criteria.
This entails performing the action which minimizes the worst-case scenario.
In this game the worst-case scenario is guessing a word which removes the
fewest number of possible remaining guesses.
Therefore, we want to guess a word that minimizes the maximum the number of
possible words left.
That is
\[w^* = \argmin_{w} \max_{w'} \ell(w,w')\]
where \(w, w' \in \mathcal{W}\) and \(\ell(g,s)\) is the number of words left
in \(\mathcal{W}\) if you guess \(g\) and \(s\) is the secret.
In this strategy you make the minimax guess, update the list of possible words
\(\mathcal{W}\), and repeat until you get it correct.
Greedy Probabilistic Guessing
Another approach would be to choose the most probable word.
There is more than one way to meaningfully define how likely a word is to be
the secret.
In this case we choose the word with the most likely letters in each position.
It is fairly straightforward to define probability here based on frequency
in the word list.
This local optimality is what makes the method greedy.
However, just choosing the most likely letter for each position will sometimes
produce invalid words.
So we can sort the letters based on probability and run down the list until a
valid word is found.
The first valid word will be our guess.
Genetic Algorithm
So far these approaches have all been deconstructive.
They attempt to deduce the best word from a large list of possible words.
We can also try a constructive approach where we learn how to generate
good guesses.
A genetic algorithm is great for this.
The idea of a genetic algorithm is to continually evolve and mutate a
population, while imposing natural selection until the members reaches some
objective.
We begin with a population of words \(P\) such that
\(P \subseteq \mathcal{W}\).
Then we perform selection to find the most fit members of \(P\) and
“breed” them using crossover.
Finally, members are subject to mutation, inversion, and permutation.
After some fixed number of generations the most fit word is used as a guess.
There is a lot to unpack here, so let me explain in a bit more detail.
First, is the fitness function.
We need some objective to compare words in \(P\) and determine which are better.
For this we can modify a metric from
[2].
That fitness function is
where \(g_i\) is the guess from turn \(i\), \(c_i\) is the number correct from
turn \(i\), \(m_i\) is the number misplaced from turn \(i\),
\(\textrm{correct}(g,s)\) is the number of correct letters for guess \(g\) and
secret \(s\), and likewise for \(\textrm{misplaced}(g,s)\).
This works by assuming \(w\) is the secret word and measuring how well that
assumption lines up with our observations so far.
Next you need to simulate natural selection on \(P\) to determine which words
die out or have the opportunity to repopulate.
There are many good ways to do selection
[3].
Here we use tournament selection, where a random subset of \(P\) is
selected and a tournament is held to decide who gets to move on.
The highest fitness value determines the tournament winner.
Once selection has occurred crossover takes place.
During this phase random pairs are selected as parents and with some probability
\(p_{\textrm{crossover}}\) they perform crossover.
This action involves choosing a random pivot in the word and splitting each
parent at that pivot.
The parents have 2 children which are made from joining different parts from
each parent.
For example, if “stage” and “slate” are the two parents, then one pivot might
lead to “slage” and “state” as children.
These children will move on to the next generation.
Finally, each child might mutate with probability \(p_{\textrm{mutate}}\),
invert with probability \(p_{\textrm{inversion}}\), and permute with
probability \(p_{\textrm{permutation}}\).
These are each straightforward random changes to the word and are
typically set up to happen with low probability (i.e. 3% chance).
This process happens a fixed number of generations \(N\).
The word with the highest fitness after the last generation is selected as the
guess.
Comparing the Strategies
Each of the above strategies I implemented
here
and simulated 5000 games with to measure their performances.
Since the genetic algorithm has many different parameters I used Tree Parzen
Estimation [4]
over 200 iterations to find a good parameter set.
The results are presented below.
The genetic algorithm wins in the average case with the lowest average and
highest percentage of games won.
It also ends up being the slowest, but at ~0.15 seconds per game it is still
a feasible solution.
Minimax and the probabilistic approaches also work very well winning ~98% of
their games.
Unfortunately, none of them guarantee a win.
They all had between 1 and 2 percent of games take over 6 turns, but this is
still an acceptable win rate.
What was most interesting to me is how well the random approach worked.
If you know the list of possible solutions \(\mathcal{W}\) and you continually
guess random words from \(\mathcal{W}\) removing impossible ones each time, then
you will still win ~92% of the time in 5 guesses on average.
It turns out it is entirely realistic to know the set of words for this game
as I discuss below.
And since the other strategies take ~4 guesses on average this shows that
using a strong guessing strategy over a random one will only save you 1
guess in the average case.
Playing Unfair
These strategies are all great, but they ignore an important fact: Wordle is an
entirely browser based game.
There is no session, account, or server sending new words to you.
This means the code for the entirety of the game is stored in your browser
while you play it.
You can view the source, albeit it has been minified making it difficult to
decipher.
Knowing the Right Words
Even with the minified JS code it is easy to see there are two ginormous
word lists.
One with ~2000 words, \(\mathcal{W}^{(1)}\), and the other with ~10,000,
\(\mathcal{W}^{(2)}\).
Upon inspection it becomes clear that \(\mathcal{W}^{(1)}\) is the list of
possible secret words.
Furthermore, \(\mathcal{W}^{(1)} \cup \mathcal{W}^{(2)}\) is the set of words
the game will allow you to guess.
Knowing the list of possible secret words allows us to make better guesses by
choosing exclusively from this list.
This is how the results above were computed.
Additionally, since \(\lvert\mathcal{W}^{(1)}\rvert \approx 2000\) this list is
much smaller than the list of all 5 letter english words.
Even
a list of only common english words
has ~16,000 entries with 5 letters.
Knowing THE Word
If you look even further for patterns in these lists you will find that the
secret word is selected based on the number of days since the game’s release.
If it has been \(i\) days since June 19th, 2021, then the secret word will be
the \(i\)-th element of \(\mathcal{W}^{(1)}\).
This makes the game trivial as you know what the secret word will be for any
given day.
You can also simply look at the local memory store in your browser
where a game state object stores the secret word in plain text.
However, neither of these are foolproof as the developers could change how the
secret word is selected and stored whenever they want.
Extra: Best First Guess
Looking through the source code for the secret word is pretty much cheating
and takes away the fun of the game.
Also using a computer to make guesses is an interesting coding and game theory
project, but is, alas, incredibly boring.
One hint we can get from computers though is what the best first guess
might be.
As with the solvers you can approach this in several different manners.
The best guess might be the one which has the most frequent letters or it
could be the word which satisfies the minimax criteria.
Looking exclusively at \(\mathcal{W}^{(1)}\) I have found “slate” to be the
best first guess for each of my algorithms.
“cares” and “soare” (the latter which
this article
suggests) are also good first guesses.
They are not in the list of possible secret words, but they remove a lot of
options.
If we select words strictly from \(\mathcal{W}^{(1)}\)
“raise” removes 2078.5 possible words from \(\mathcal{W}^{(1)}\) on average.
“cigar” removes the most with 2314 words removed when “sugar” is the key.
If we can choose any word from \(\mathcal{W}^{(1)} \cup \mathcal{W}^{(2)}\),
then the highest average is “soare” with 2095.479 removed words on average.
“cigar” removes the most with 2314.0 words removed when the key is “sugar”.
]]>Daniel NicholsHomemade Noises Part 1: Making Things Louder2021-08-04T00:00:00-04:002021-08-04T00:00:00-04:00https://dando18.github.io/posts/2021/08/04/homemade-noises-part-1Messing around with guitar pedals and finding fun sound combinations is a blast and often
a needed distraction from practicing. Pedals, however, are expensive at $100-300 a pop,
which makes it rather difficult to own enough to play around with (or any at all in my
case). Guitar stores will let you try some, but it is cumbersome to set up a chain in
a store and they will eventually kick you out.
Thus, I took the deep plunge into figuring out how they work, so I could build some of my
own. Luckily, there are some pretty great forums on the internet about guitar pedals
where I could learn all about them. And Wikipedia has an abundance of information
on circuits and provides plenty of little theory rabbit holes.
I have a little bit of experience with building circuits, but significantly less with
designing them, so I began with a simple boost pedal. A boost pedal “boosts”
the signal by adjusting the gain. This is useful for dynamics when playing. Some boost
pedals will have several other features built-in, such as an equalizer, but for
simplicity I stuck with a single parameter boost.
The circuit is based on this Tayda booster.
I replaced the 1N4148 diodes with 1N34A germanium diodes and used a red LED (lower voltage drop).
The germanium diodes clip at about half the voltage giving more fuzz to the sound. Using the
1N4148’s would give a cleaner tone.
The above circuit is an example of an N-channel MOSFET
common-source amplifier.That is a mouthful,
so I will try to break it down.
The most important component in this circuit is Q1, a transistor. It is a BS170 transistor
(same, but higher rated than the popular 2N7000), which is a special type of transistor
called an N-channel MOSFET. Transistors do not have
to just be used for switching. They can also be utilized to amplify signals via
biasing. This is great because that is exactly
what a booster pedal should do: amplify the signal.
One way to amplify signals with FET (JFET or MOSFET) transistors are common-source circuits.
These have the gate (2) and drain (1) both tied to power and the source (3) to ground
(or vice versa). These pages [1,
2] provide in-depth
explanation as to how these circuits work.
To get maximum voltage gain out of the drain (1) we need to bias the input to the gate (2).
There are several biasing techniques,
which use resistors and two DC sources to bias. However, you can also forward bias a transistor
with zener diodes. This is helpful since the diodes are independent of the supply voltage.
I end up using germanium diodes, which are the same, but start to forward bias at a much
lower initial voltage.
I should note that op-amps are a
popular component used for amplification. They amplify signals well, are small, and
are now very cheap (~$0.25 each). But op-amps themselves are just small integrated circuits
with cascaded transistor amplifiers inside.
For larger pedals with boosting stages it makes sense to use simple op-amps instead
of separate transistor circuits, however, for a single booster pedal it feels like
cheating.
The transistor-based amplifier is the meat of the circuit and how it “boosts” the guitar signal.
There is also a status LED light, and connections to the potentiometer knob, stomp switch,
input/output jacks, and power jack.
Assembly
The circuit is fairly simple and based on a previous successful design, so I did
not mess around with breadboarding and directly ordered a PCB. D1 and D2, the diodes,
are the only components I would want to mess around with as they will control
the amount of distortion. I did not, but you could put pin headers on the PCB
so it is easier to swap out diodes and try different ones.
With the PCB in hand it is just a matter of soldering everything together. Due to
its size this board does not take very long to assemble.
Decoration
Every pedal hoarder should know that the aesthetics are paramount to good sound.
Not really, but I am much more likely to put a pedal on display if it looks good
and I am then, in turn, more likely to use it if I see it frequently.
After some practice I finally nailed the C&H design.
Sound Test
With the aesthetics out of the way we can finally plug it in and see what it
sounds like.
Summary and Improvements
The pedal sounds great for a clean booster, it only cost ~$20, and assembly
took about an hour. Sourcing parts and ordering them took a while, but now that I
have bulk sets of components I will not need to go through as much sourcing next
time.
Simple boosting circuits are a good segue into bigger overdrive/distortion/fuzz
circuits. They operate off of the same concept of diode + amplifier. Usually op-amps
are used in place of transistor circuits. Additionally, cascoded
amplifier circuits are utilized which use several amplifier circuits together
with various diode biasing to achieve more distortion effects.
]]>Daniel NicholsVisualizing the Simplex Algorithm2021-01-12T00:00:00-05:002021-01-12T00:00:00-05:00https://dando18.github.io/posts/2021/12/visualizing-the-simplex-algorithmThe simplex algorithm is a fundamental result in linear programming and optimization. Being remarkably efficient the algorithm quickly became a popular technique for solving linear programs. Having an optimal algorithm is essential, since linear programming is ubiquitous in business analytics, supply chain management, economics, and other important fields. In addition to being efficient the algorithm has a clean and intriguing visual intuition. I will first give some background on linear programs, then show how we can visualize their solution space, and finally how to utilize this to solve linear programs.
Linear Programming is the practice of minimizing or maximizing a linear objective with respect to linear constraints. Before diving into the notation and general definitions lets motivate it with an example problem.
You are a coffee roaster and you are trying to determine how many 60lb bags of green coffee beans to order from farms A, B, and C. You know you need 50 bags to meet this years demand and that farms A, B, and C charge $100, $115, and $90 per bag, respectively. You also must purchase at least 5 bags from each farm in order to maintain an on-going business relationship. Additionally, farms A, B, and C can only sell up to 30, 25, and 20 bags, respectively.
You find your business in this situation and you want to minimize your total expenses. By expressing each known constraint mathematically we can form a linear program. Let the total number of bags purchased from A, B, and C be represented by \(a\), \(b\), and \(c\), respectively.
\[\begin{aligned}
\textrm{minimize} \quad& 100a + 115b + 90c \\
\textrm{subject to} \quad& a + b + c = 50 \\
& a,b,c \ge 5 \\
& a \le 30 \\
& b \le 25 \\
& c \le 20
\end{aligned}\]
In this instance we find that \(a=25\), \(b=5\), and \(c=20\) gives the optimal price of \(\$ 4875\).
The above problem is not too difficult and could probably be solved by hand, but as the number of variables and constraints grows this becomes impossible. Thus, we rewrite the linear program in a more general form and try to find solutions for the general case using computers. Let \(\bm x\) be the vector of variables we desire to optimize. Then the linear objective can be expressed as \(\bm c^\intercal \bm x\) where \(\bm c\) contains the multiples of these variables. Likewise we can express constraint \(i\) as \(\bm a_i^\intercal \bm x \le b_i\). If we let \(A=[\bm a_1, \bm a_2, \ldots, \bm a_n]^\intercal\) be a matrix with each \(\bm a_i\) as row \(i\), then our constraints become \(A\bm x \le \bm b\). And finally requiring that \(\bm x \ge 0\) we get
\[\begin{aligned}
\textrm{maximize} \quad& \bm c^\intercal \bm x \\
\textrm{subject to} \quad& A\bm x \le \bm b \\
& \bm x \ge 0
\end{aligned}\]
as our general case. If we want to minimize, then we can maximize \(-\bm c^\intercal \bm x\) instead.
Notice in the coffee example we have an equality constraint \(a+b+c=50\). We can accomplish this in the general form by changing the constraints to \(A\bm x = \bm b\) and adding slack and surplus variables. For example, if we have the constraints \(a+b \ge 5\) and \(b-c \le 2\), then we can change these to \(a+b -s = 5\) and \(b-c +t = 2\). Here we add the variables \(s\) and \(t\) to \(\bm x\) and since \(\bm x \ge 0\) the inequalities still hold. And so our general form changes slightly to
\[\begin{aligned}
\textrm{maximize} \quad& \bm c^\intercal \bm x \\
\textrm{subject to} \quad& A\bm x = \bm b \\
& \bm x \ge 0
\end{aligned}\]
The Solution Space: A Geometric Understanding
When solving a constrained optimization problem the constraints limit possible values of \(\bm x\), while you try to optimize some function of \(\bm x\). This set of possible values for \(\bm x\) is called the solution space. Somewhere within the solution space there is an \(\bm x\) that maximizes \(\bm c^\intercal \bm x\). In the case of linear programming the solution space is defined by values of \(\bm x\) such that \(A\bm x \le \bm b\) and \(\bm x \ge 0\) (we will consider the \(\le\) case, but the canonical form with slack variables is equivalent).
In general we might know very little about a solution space, but in the case of linear programming we know quite a bit. The possible values of \(\bm x\) such that \(A\bm x \le \bm b\) and \(\bm x\ge 0\) forms a convex polytope. A polytope is a geometric object with only flat sides. The more familiar polygon is an example of a 2D polytope. The fact that the polytope is convex means that if you pick any two points within the shape, then the line segment connecting them is entirely within the shape (i.e. \(\beta\bm x + (1-\beta)\bm x \in \textrm{Shape}\,\, \forall \bm x \in \textrm{Shape}\,\,\forall \beta\in[0,1)\)). Put simply: the shape is not really jagged, but more somewhat plump. Below is an example of a convex polytope generated from a set of linear constraints.
So what makes the constraints form a polytope? First, consider what each individual constraint means geometrically. If we have \(n\) variables in \(\bm x\), then each \(\bm a_i^\intercal \bm x = b_i\) forms an \(n\)-dimensional hyperplane. In 2D this is a line, 3D a plane, and so on… Then \(\bm a_i^\intercal \bm x \le b_i\) divides two sets of points. Those below or on the hyperplane \(\bm a_i^\intercal \bm x - b_i = 0\) are included in our solution space and the rest are not.
When we take \(A\bm x \le \bm b\), then we have numerous hyperplanes and the space enclosed by their intersections is our solution set. In 2D this is clear to see. If you draw a bunch of lines at random, then the space enclosed by them will form a polygon. Likewise in 3D if you position a number of sheets of paper in different orientations (assume they can intersect), then you will form a 3D polytope.
If you tried picturing this, then you might have noticed two cases where the above is not necessarily true. First, if there are parallel hyperplanes there will be no solution space. Thus, with an empty solution space we conclude that there are no solutions. In the second case we might have an unbounded region meaning that one of the sides of the polytope is not “closed” and the region spills into infinity. This is easily pictured in the 2D case by \(y>x\) and \(y>-x\). This case requires some special handling by the algorithm, but still fits within the intuition of the solution.
Finding Ideal Solutions: Two Observations
Our problem has now been reduced to maximizing \(\bm c^\intercal \bm x\) such that \(\bm x\) is a point in the polytope defined by the constraints. While we have reduced the set of possible points significantly, there are still an infinite number of possible values of \(\bm x\) since the polytope is a convex subset of \(\mathbb{R}^d\). The above geometric understanding is not enough to make this problem possible in finite time. However, we can rely on two observations to simplify the problem further.
First, if the maximum value exists within the solution space, then it will be on at least one of the polytope’s extreme points [1]. The extreme points are essentially the “corners” of the shape. This observation significantly reduces the search space as a convex polytope will always have a finite number of extreme points.
So now we have reduced the search space to a finite number of possible \(\bm x\). However, it turns out that in practice the number of extreme points is still too large to compute in a reasonable amount of time. This leaves us with a finite possible \(\bm x\), but there are too many to search them all for the max of \(\bm c^\intercal \bm x\). We need a smarter way to traverse the extreme points of the polytope, so that we do not have to try them all. This is where the second observation comes in.
If an extreme point does not give the maximum, then it has at least one edge to another extreme point such that \(\bm c^\intercal \bm x\) is strictly increasing along that edge [1]. Thus, the extreme point on the other end of the edge gives a higher value than the current extreme point. So to find the maximum we first pick an extreme point and continually jump to neighboring extreme points with higher objective values until we reach one with no neighbors giving higher objective values. This point is a value of \(\bm x\) such that \(\bm c^\intercal \bm x\) is maximized.
The Simplex Algorithm
The simplex algorithm makes use of these observations to find solutions to linear programs. It largely involves translating these geometric intuitions into a computer friendly format. You can probably stop reading here if you are not interested in this sort of thing as we now move from a clean geometric intuition to more dense mathematics. Additionally, there are lots of great linear programming libraries which implement the simplex algorithm for you and some languages, such as AMPL and R, have built-in solvers.
As mentioned we need a computer friendly format for our geometric intuition as computers cannot natively process polytopes and it seems like a headache to write software which can. So what format do computers like? Matrices. Yes, tables of numbers are highly addictive to computers. Now we need to rephrase our problem in terms of matrix operations. To do this let us define something called the tableau form:
\[\begin{bmatrix}
1 & -\bm c^\intercal & 0 \\
\bm 0 & A & \bm b \\
\end{bmatrix}\]
While this tableau form might be the input to a computer program, it is still not the ideal starting point for the algorithm. Most implementations will first rearrange the tableau into the canonical tableau form. This is done by rearranging the \(A\) matrix. Notice that we can re-order the columns of \(A\) without effecting the result. A tableau can be put in canonical form if the columns of \(A\) can be swapped around such that it contains an identity matrix. Thus, the above tableau can be rewritten in canonical form as
\[\begin{bmatrix}
1 & -\bm c^\intercal_B & -\bm c^\intercal_D & 0 \\
\bm 0 & I & D & \bm b \\
\end{bmatrix}\]
which, using row-addition operations, can be rewritten as
\[\begin{bmatrix}
1 & 0 & -\hat{\bm c}^\intercal_D & z \\
\bm 0 & I & D & \bm b \\
\end{bmatrix}\]
Now the variables corresponding to the columns in the identity matrix are called basic variables, while the rest are free variables. If we set all the free variables to \(0\), then we can simply solve for the basic variables as they will just be the corresponding value in \(\bm b\). These values give a basic feasible solution, which is the same as choosing the first extreme point on the polytope.
Now we can start moving along the edges to better extreme points. In the tableau form this is represented by pivot operations. The pivot operation is, in fact, very similar to the pivot in Gaussian elimination. Choosing a pivot element as a non-zero entry in free variable column, then we can multiply this row by the reciprocal of the selected number to make it \(1\) and then add multiples of the row to the other rows until all their entries in the selected column are \(0\). This now transforms the column from a free variable to a basic variable. It will also replace the corresponding variable in the identity matrix. The added and replaced variables are called entering and leaving variables, respectively.
Choosing the entering and leaving variables to pivot each iteration is somewhat implementation dependent. For the entering variable we want to choose the column corresponding to the most negative value of the first row (with \(-\bm c^\intercal\) in it). This will cause the largest derivative and likewise largest increase in the objective function. If you have chosen the column, then the row must be selected such that the solution is still feasible.
Iteratively this process continues until the first row has all positive objective values. When this happens no choice of pivot will further maximize the objective. This corresponds to finding the final extreme point on the polytope.
This was just a brief overview of the algorithm and how it connects with geometrical intuition. There are significantly many more implementation details to bother with as well as adaptations/improvements to the algorithm [2]. You can read more about simplex here, here, and here.
]]>Daniel NicholsBaby Yoda’s Plot2020-12-19T00:00:00-05:002020-12-19T00:00:00-05:00https://dando18.github.io/posts/2020/19/baby-yodaAfter enjoying the incredible season 2 finale of The Mandalorian I was inspired to represent baby yoda in his truest form: mathematical.
If you are a sane human and have no idea how these1 parametric equations2 are baby yoda, then here is their wonderful plot:
And in the sake of the Christmas spirit here is another.
which looks like:
Footnotes
1I had quite a difficult time getting the equation to display directly in the browser and even \(\LaTeX\) for that matter, hence, I put the ginormous image file in the middle of the page. So here are the equation’s .tex files for the first and second equations if for some odd reason you want them.↩
2In both of the above set of parametric equations we have \(0\le t \le 36\pi\) and \(\theta(\cdot)\) is the Heaviside step function↩
]]>Daniel NicholsVisualizing Gradient Descent and Its Descendants2020-11-28T00:00:00-05:002020-11-28T00:00:00-05:00https://dando18.github.io/posts/2020/28/visualizing-gradient-descentGradient descent has become ubiquitous in computer science recently largely due to its use in training neural networks. While neural networks are somewhat complex, gradient descent is a very simple, intuitive tool.
This statement may seem foreign, but visualizing gradient descent helps uncover the mystery behind the gradient and its properties.
Intuition and Visualization
If you are not familiar with gradients, they have a nice intuitive property which lets this update rule work. The gradient of a function \(f\) at a point \(\bm x\) always points in the direction of steepest ascent. Intuitively, if you are on the side of a mountain, then the gradient at your location would be the direction of the steepest step you can take. If you want to reach the peak of the mountain, then continually taking steps in that direction is a good strategy. Now you may not reach the absolute highest peak on the mountain, but you will reach a peak.
Following the same intuition if we take the negative gradient (\(-\nabla f(\bm x)\)), then this points in the direction of steepest descent. So if we continually take steps in this direction (\(-\eta \nabla f(\bm x)\)), then we will eventually reach a local minimum. Here \(\eta\) defines the size of the step we take.
You can see an example of this process below. The paths on the two plots show the path of gradient descent travelling down the slope. Try different functions in the select box. Also try changing the step size and seeing how it effects the path and number of iterations needed. You can click on a point in the contour plot (on the right) to set a new starting point.
Momentum
As you can see from the above minimization it can sometimes take a large number of iterations to find an optimal minimum. One of the reasons is we are taking such small steps repeatedly. However, in the general case (and with more than 3 dimensions) its difficult to determine how large of a step to take. This is where Nesterov Momentum comes in. The name momentum aptly describes how this adjustment to gradient descent works. If we continue to travel in the same direction, then increasingly take larger steps until we have found a minimum. This is similar to how one would gain momentum rolling down a hill.
Let \(v\) give the velocity of the descent. Then we can define our update rule as
A more recent adaptation by Kingma et al [1] called Adam has quickly become the most popular gradient descent derivative in use today. A large portion of neural network training uses Adam to find optimal parameters for the network. Adam is based off of adaptive moment estimations, which is where it gets its name.
The main improvement in Adam is that each parameter is given an adaptive learning rate (or step size). In vanilla gradient descent there is a static step size \(\eta\) for all values of \(\bm x\) and every iteration. Adam gives a unique step size to each \(\bm x_i\) and updates them every iteration using the first and second moments of the gradient. Here the first moment is the mean of the gradient and the second the uncentered variance. Since computing these directly would be computationally burdensome we use running averages to calculate approximate moments. Let \(\bm m\) be the first approximate moment and \(\bm v\) the second. If we initialized these to zero, then they can be calculated at iteration \(i\) as
If you expand the values \(\bm m_i\) and \(\bm v_i\) it is clear to see that the above formulas produce biased estimators of the moments. That is \(\mathbb{E}[\bm m_i] = \mathbb{E}\left[\nabla f(\bm x_i)\right] (1-\beta_1^i)\) and \(\mathbb{E}[\bm v_i] = \mathbb{E}\left[\left(\nabla f(\bm x_i)\right)^2\right] (1-\beta_2^i)\), which are biased by \((1-\beta_1^i)\) and \((1-\beta_2^i)\), respectively. To fix this we adjust the bias after computing the above updates.
for some small \(\varepsilon > 0\). The \(\varepsilon\) is included to avoid division by zero, when \(\bm v_i=\bm 0\). According to [1] the values \(\beta_1=0.9\), \(\beta_2=0.999\), and \(\varepsilon=10^{-8}\) are ideal for almost all problems. The rate \(\eta\) is subject to change, but small values between \(0.001\) and \(0.01\) are often ideal.
Use in Neural Networks
So how does this simple “walking down hill” optimization let us train neural networks for complex tasks like facial recognition? The intuition is very simple. Neural networks are mathematical functions, which take in a piece of input data and a set of parameters and makes a prediction about what the input data is. Call this function \(f(\bm x, \bm \theta)\). Here \(f\) is the neural network, \(\bm x\) is the input data, and \(\bm \theta\) are the parameters. Now let \(y_i\) denote the actual class of \(\bm x_i\) (i.e. dog or cat) and \(f(\bm x_i, \bm \theta)\) is what our neural network predicted \(\bm x_i\) is.
Using these definitions we can define the error of the network as some loss function \(\mathcal{L}(f(\bm x_i, \bm \theta), y_i)\), which takes the prediction and ground truth and returns the error of misclassifying sample \(\bm x_i\). This gives us a mathematical definition for the classification error of the neural network, which can be minimized with gradient descent. And this is exactly what we want: minimal classification error.
This formulation and intuition are pretty simple, but in practice computing \(\nabla_{\bm \theta_i} \mathcal{L}(f(\bm x, \bm \theta_i), y)\) is non-trivial. For starters, calculating the true gradient is often impossible. We do not have access to all possible values of \(\bm x\) and \(y\) (think about \(\bm x\) is an image and \(y\) is whether that image is a dog or cat). Even if we restrict our problem domain to a small data set, then its still computationally difficult to compute the entire gradient. To alleviate this we use something called stochastic gradient descent (SGD) and/or batch SGD. Here we pick a random input sample or random batch of input samples at each iteration to compute an approximate gradient.
The other issue here is that gradient descent is only guaranteed to find a global minimum if the function is convex (like the quadratic example from above). Otherwise it might only find local minima. In the case of neural networks \(f\) is highly non-convex. It is not completely understood why local minima work so well for neural networks, but who is gonna complain?
Machine Learning in General
In general if we can model the classification error or loss of a machine learning predictor as a mathematical function, then we can apply gradient descent to optimize it. Consider the linear classification model \(f(\bm x; \bm \theta) = \bm \theta^\intercal \bm x + \theta_0\). We can model the error of \(f\) as the mean squared error
This is example is slight overkill since linear least squares has a closed form solution, but it shows the general idea quite well.
]]>Daniel NicholsOn Graph Theory and Social Distancing2020-11-15T00:00:00-05:002020-11-15T00:00:00-05:00https://dando18.github.io/posts/2020/15/on-graph-theory-and-social-distancingCOVID-19 has posed unique challenges to the world and forced people to adapt to new ways of living. For example social distancing has become the norm in public spaces. In the U.S. keeping people 6 feet apart has become a rigid requirement in any social gathering. While sitting at some of these events, I have started to wonder: is this socially distanced arrangement optimal? So I began to investigate.
First, we need to define optimal. One definition might say an arrangement is optimal if it fits the most amount of people within an area, while preserving social distancing measures. However, this might not be useful as various governments have imposed hard limits on the number of people allowed to gather. So we could, given a fixed number of people, define optimal as maximizing the minimum distance between people. Or if we are feeling adventurous we could define some function \(g_{\lambda}(p, d) = \lambda_p p + \lambda_d d\) as the weighted sum of the minimum distance between any two people and the total number of people seated and maximize \(g_{\lambda}\).
All of these measures of optimality make sense, but what are we optimizing exactly? I have used the word “arrangement” without really giving it a definition, so let me present two possible ways to approach this problem. First, we could have a fixed number of available positions and we need to map persons to those positions in such a way that preserves social distancing. For instance, an auditorium has fixed seating and we need to assign people to those seats in an optimal and safe way. Now consider we can move those seats around. This leads us to the second approach, where we need to find an optimal set of points within a region to place people safely.
Now we have 3 measures of optimality over 2 possible problem spaces leading to 6 fun optimization problems to work through. None of these consider the extra free-variable, which is grouping. Often people who co-habitate are permitted to be within 6 feet of each other. At least for the second problem space (non-fixed seating) we can treat groups as single entities and the same solutions work. For the first, we need some smarter solutions, which I address at the end. I should also note that most of my solutions are for the general case and thus somewhat complicated. Finding optimal configurations with the assumption of some regularity is often much easier, but what is the point of being in graduate school if you are not going to show the general case.
Here we have a fixed set of seats \(V\) and we want to find an optimal choice of seats \(S \subseteq V\) such that \(\lvert S\rvert\) is maximized. This can be thought of as a nice graph theory problem. Define \(\mathcal{G} = \left(V, E\right)\) where \(E = \{\left(v_i, v_j\right) : v_i,v_j \in V \land i\ne j \land D(v_i, v_j) < d \}\), where \(D(v_i, v_j)\) is the euclidean distance between two seats and \(d\) is some distance threshold (i.e. 6 feet). Now \(\mathcal{G}\) is a graph where a seat is connected to another seat if the social distancing rule were to be broken if both seats were occupied.
Thus, the set \(S\) must only contain vertices of \(\mathcal{G}\) which are not connected by an edge. Such a set of vertices is called an independent set and we want to find the largest independent set of \(\mathcal{G}\). This is the same as finding the maximum clique of the complement graph \(\overline{\mathcal{G}}\).
On one hand this is great, because finding maximum cliques is a very well studied area of graph algorithms. On the other hand, this is bad news because it is an NP-Hard problem; it is hard to solve, check solutions, and even find approximations. There are algorithms better than the \(\mathcal{O}(2^nn^2)\) brute-force algorithm, but they are still in NP. Currently, the best algorithm runs in \(\mathcal{O}(1.1996^n)\) with polynomial space complexity as proven by Xiao et al [1], which means we could only feasibly apply this algorithm for up to ~100 seats. And even worse is that finding maximum independent sets on a general graph is \(\mathsf{MaxSNP}\mathrm{-complete}\) meaning it has no polynomial-time approximations which produce a result within a constant \(c\) multiple of the optimal solution.
Luckily there is some prior knowledge about the construction of \(\mathcal{G}\), which we can use to simplify the problem. If \(\Delta = \max_{v\in V} \deg v\) is the maximum degree in \(\mathcal{G}\), then we can say \(\Delta\) is independent of \(\lvert V \rvert\). That is \(\mathcal{G}\) is a degree-bounded graph. We can make this assumption because the number of seats within \(d\) distance of a seat should not grow unbounded as the total number of seats grows. Otherwise you have a very dense seat packing, which is not physically possible. Likewise, this means \(\mathcal{G}\) is a sparse graph with bounded degree. Halldórsson et al [2] show that assuming bounded degree allows for a polynomial-time algorithm to find approximate maximum independent sets where the approximation always has a constant ratio \(\frac{\Delta + 2}{3}\) of the optimal solution. Their greedy algorithm is actually quite simple in that you just continually remove the vertex with the highest degree until the graph is entirely disconnected. You can see an example of this algorithm below, where each black dot could be considered a “seat” and they are connected if they are within 6 ft of each other. The red dots are then a good selection of placements to put people safely.
Using this we can also give some bounds on \(\alpha(\mathcal{G}) = \lvert S \rvert\) (also called the independence number of \(\mathcal{G}\)). Most of these I pull from W. Willis [3]. Let \(\bar{d}\) be the average degree of \(\mathcal{G}\), \(n\) be the number of vertices, \(e\) the number of edges, and \(\lambda_n\) be the \(n\)-th eigenvalue (sorted order) of the adjacency matrix. Then we can define the following lower bounds on \(\alpha\):
and several others… These are helpful in determining how many we can seat at least on a given graph. For instance, consider a rectangular lattice of seats with \(d\) unit length and the minimum distance people must sit apart is \(\sqrt{2}d + \varepsilon\) for some small \(\varepsilon > 0\). Recall that we assumed \(\mathcal{G}\) is sparse with bounded degree. Thus, \(\Delta(\mathcal{G}) = 8\) is independent of the number of seats \(n\). So we know that we will be able to seat at least \(\frac{n}{9}\) people in this lattice arrangement. But in this case we can give an even tighter bound with the last one (we can assume \(\sqrt{n} \in \mathbb{Z}^+\)):
Now \(\left(\frac{1}{9} (\sqrt{n}-1)^2 + \frac{2}{3}(\sqrt{n}-1) + 1\right) - \frac{n}{9} \to \infty\) as \(n \to \infty\), so this is an increasingly better lower bound than the first. So given 100 chairs in this lattice configuration and no one can share adjacent chairs, then you can sit at least 16 people according to this lower bound. This is not the tightest lower bound and in fact you can do better.
We can also give some upper bounds on \(\alpha\) (from [3]). Let \(\delta = \min_{v \in V} deg(v)\) be the minimum degree of \(\mathcal{G}\).
\[\alpha \le n - \frac{e}{\Delta}\]
\[\alpha \le \left\lfloor \frac{1}{2} + \sqrt{\frac{1}{4} + n^2 - n - 2e} \right\rfloor\]
\[\alpha \le n - \left\lfloor \frac{n-1}{\Delta} \right\rfloor = \left\lfloor \frac{(\Delta-1)n + 1}{\Delta} \right\rfloor\]
\[\alpha \le n - \delta\]
and some others… These are likewise helpful in determining whether a given arrangement could hold the desired amount. Returning to our lattice example from above we can take \(e = 2(\sqrt{n}-1)(2\sqrt{n}-1)\) and use the first upper bound. This gives
which, for 100 seats, implies \(\alpha \le 57.25\). So now we know \(16 \le \alpha \le 57.25\), which are not great bounds, but bounds nonetheless. In fact, for the particular lattice problem I brought up (with \(\Delta(\mathcal{G}) = 8\)) we can say that \(\alpha(\mathcal{G}) = \left\lceil \frac{\sqrt{n}}{2} \right\rceil^2\). Thus, with 100 seats we can seat at most 25 people safely. We will not have this nice closed form for every problem though, so the upper and lower bounds are important.
In summation, making assumptions about the connectivity of our graph allows us to use efficient approximations. In addition, we can calculate certain guarantees based on simple graph invariants. However, this solution is somewhat overkill as fixed positions are often seats, which are usually in some regular pattern. As with the lattice pattern above it is fairly trivial to find a closed form solution based on regularity, but it is still good to have a solution for the general case.
Maximum Distance
Here we have a fixed number of people \(N\) that we need to sit with maximum separation. We want to find a set of vertices \(A \subseteq V\) such that \(\lvert A \rvert = N\) and the minimum distance between any two vertices is maximum. More formally this is written as
\[\begin{aligned}
\textrm{maximize} \quad& \min_{i \ne j} D\left(v_i, v_j \right) \\
\textrm{subject to} \quad & v_1, \ldots, v_N \in A \subseteq V \\
\quad & \lvert A \rvert = N
\end{aligned}\]
This problem is known as the discrete p-dispersion problem and, again, has a decent amount of literature surrounding it. Unfortunately it is another computationally difficult problem. This can be shown by an interesting relationship to the independent set problem from above. First, let \(\mathcal{G}_d\) be defined by the same graph as above with minimum distance \(d\) and let \(\mathcal{X} : \mathbb{R} \mapsto \weierp(V)\) be defined by
\[\mathcal{X} (d) = \left\{ A \mid A \subseteq V \land \lvert A \rvert = p \land \mathbb{I}\{x\in A\} + \mathbb{I}\{y\in A\} \le 1 \,\,\forall (x,y) \in E\left(\mathcal{G}_d\right) \right\}\]
where \(E\left(\mathcal{G}_d\right)\) are the edges of \(\mathcal{G}_d\) and \(\mathbb{I}\) is the indicator function. The above max-min problem can be re-written as
\[\begin{aligned}
\textrm{maximize} \quad & d \\
\textrm{subject to} \quad & \mathcal{X}(d) \ne \emptyset \\
\quad & d \ge 0
\end{aligned}\]
Notice that \(\mathcal{X}(d)\) is the set of all size \(N\) independent sets of \(\mathcal{G}_d\) with a minimum separation of \(d\). So we want to maximize \(d\), such that a size \(N\) independent set exists within \(\mathcal{G}_d\). The independent set decision problem is \(\mathsf{NP-complete}\) as it is closely related to the minimum vertex cover decision problem.
Assuming the above maximization is feasible it can be solved using binary search on the list of possible distances \(d\) and an independent set decision algorithm for feasibility testing. The list of possible values for \(d\) is all the distances in the full graph \(\mathcal{G}_{\infty}\). Thus, if \(d_{max}\) is the maximum distance between any two vertices in \(\mathcal{G}\), then the algorithm will run the independent set decision problem \(\mathcal{O}(\log d_{max})\) times. The algorithm is still in \(\mathsf{NP}\) because of this, but is still feasible for smaller graphs (roughly \(10^3\) seats). Sayah et al propose two formulations of the problem in terms of mixed-integer linear programming with reduced constraints using known bounds, which offer exact solutions [4] and can be easily solved with CPLEX.
A Compromise
Now lets get a little more general… Consider we want to find some optimal solution in-between the two above approaches. This could be phrased as maximizing a weighted sum of the total number of people seated and the minimum distance between any two people. As a function this is \(g_{\lambda_N, \lambda_d} (N, d) = \lambda_N N + \lambda_d d\). Now we can fix the \(\lambda\)’s and try to maximize \(g\). This can be formulated exactly as above, but now \(\mathcal{X}\) is a function of \(N\) and \(d\). I am also going to change the notation a bit to express the problem in terms of integer programming.
Let \(\bm{x} \in \{0, 1\}^{\lvert V \rvert}\) be a vector with an element corresponding to each vertex in \(\mathcal{G}\). If we decide to assign a person to vertex \(i\) (aka seat), then \(\bm{x}_i = 1\), otherwise it is 0. Now we can re-define \(\mathcal{X}\) as
This adds another degree of freedom to the above algorithm, but it should be fairly trivial to adapt. Since \(\lambda\) are fixed, then we can fix \(N\), which gives \(\max_{d} g_{\lambda_N, \lambda_d} (N, d)\). This is the same problem as above. Despite the intuition that \(N \propto \frac{1}{\max d}\) they are dependent on each-other so we cannot binary search \(N\) as well. We will need to exhaustively search all values of \(N\) from \(1\) to \(\lvert V \rvert\). Thus we run the independent set decision problem \(\mathcal{O}\left( \lvert V \rvert \log d_{max} \right)\) times.
Free Positions
Maximum People
Some places, such as a store, do not have fixed positions to map people into. In this case we need to find those fixed positions, which adds a free variable into the optimization search space. However, this is also a constraint relaxation making the problem much easier to solve. For this problem we want to find a set of points within a region such that each point is farther than \(d\) from all other points and we can fit the most people inside the region.
Formally, we have a space \(S \subset \mathbb{R}^2\) and we want to find a set of points \(\mathcal{X} = \{ \bm{x}_i \mid \bm{x}_i \in S \land D(\bm{x}_i, \bm{x}_j) < d\,\, \forall i \ne j \}\) such that \(\lvert \mathcal{X} \rvert\) is maximum. The provided solution actually works in \(\mathbb{R}^d\), but \(\mathbb{R}^2\) and \(\mathbb{R}^3\) are the only ones we care about.
Each \(\bm{x}_i\) has a neighborhood \(S_\epsilon\), which no other points lie within. In the 2D case this means we have a circle centered at each \(\bm{x}_i\) and none of them overlap. Now this boils down to the well studied problem of circle packing. There is an abundance of literature and software surrounding circle packing as well as available tables of existing solutions.
As an example of how to translate circle packing problems into point packing I will look at square regions. Given a square region with side length \(L\) we want to find the maximum circle packing of a square region \(L + d\) (scaled to account for 2 extra radii). Most literature focuses on packing unit circles, so to use these results we need to scale the square to \(\frac{L}{d} + 1\) and then, once a solution is arrived upon, rescale the found circle centers by \(d\).
Say we have a square region that is \(100 \times 100\) ft and we want to find the most number of seats to place such that they are all 6 ft apart. This is equivalent to finding the most number of unit circles that can be placed in the square with side length \(\frac{100 + 6}{6} = 17.\overline{6}\).
Maximum Distance
In this optimization problem we need to choose \(N\) positions in a region such that they are maximally dispersed. This can more formally be expressed as a constrained optimization problem:
This is known as the continuous p-dispersion problem and is well studied in terms of exact solutions and approximations. When \(S\) is convex this is similar to the circle packing problem of fitting the most circles in \(S\), since we can rewrite the above maximization problem as:
These are non-linear programs and exact solutions are not always feasible. One can use an optimization software such as AMPL to find good solutions for any generic convex region \(S\). However, since rectangular regions are common real-life examples I will discussion their solutions here.
Consider the region \(S \in [0, 1]^2\). We want to fit \(N\) points within this square such that the minimum distance between any two points is maximized. We also want the minimum distance to be greater than \(d\), but by maximizing the minimum we should figure out whether this is even possible or not. Any solution in \([0, 1]^2\) is valid for any square region as we can take \(\bm{x}_i \mapsto \frac{1}{2}\left(\frac{\bm{x}_i}{\lVert\bm{x}_i\rVert} + 1\right)\), which maps all \(\bm{x}_i\) to \([0, 1]^2\) and preserves the ordering of their scaled distances.
A Compromise
Much like above we can extend the discrete version by relaxing the constraint to be continuous.
\[\begin{aligned}
\textrm{maximize} \quad & g_{\lambda_N, \lambda_d} (N, d) \\
\textrm{subject to} \quad & \bm{x}_1, \ldots, \bm{x}_N \in S \subset \mathbb{R}^2 \\
\quad & d \ge 0 \\
\quad & 0 \le N \le \lvert V \rvert \\
\quad & \lVert \bm{x}_i - \bm{x}_j \rVert \le d \quad \forall i \ne j
\end{aligned}\]
This is actually a pretty difficult problem, but it can be solved similar to how we solved the compromised solution in the discrete case. For any fixed \(N\) we can solve this using the continuous p-dispersion solution. Since \(N\) is discrete, then we can just try every value from \(1\) to \(\lvert V \rvert\) and see which one maximizes \(g_{\lambda_N, \lambda_d}\).
Accounting for Groups
Now if everyone sat/stood by themselves, then all of the above mentioned techniques would work wonderfully. But in reality people who co-habitate are often allowed to be within 6 feet of each other. In the latter approach, where we are placing the seats, this is fine. We can treat “seats” as groups of seats and all of the above mentioned methods still work. However, things get a bit more complicated when we look at the fixed seating optimization problem.
For example, consider the problem where we have \(\lvert V \rvert\) fixed seats and we are trying to seat \(N\) people with maximal distance between them. One way to approach this problem is to partition the graph into subgraphs where each subgraph represents a local “neighborhood” of seats. This way each subgraph could hold multiple people. However, determining the number of partitions to use ahead of time is difficult for the general case.
For this problem let \(\bm{x}_i \in \mathbb{R}^2\) be the location of position \(i\) in euclidean space. Now define the fully connected graph \(\mathcal{G} = (V, E)\) such that each vertex is a position and there is an edge between every seat \(\bm{x}_i\) and \(\bm{x}_j\) weighted by the radial basis function:
Now seats further apart have a smaller weight than those right next to each other who have a weight of 1. We want to find a partitioning \(A_0, A_1, \ldots, A_k\) of \(V\) which minimizes the weights between A’s. This can be expressed cleanly as an objective function. Let \(w_{ij}\) be the weight between two vertices and \(W(A, B) = \sum_{i\in A \\ j\in B} w_{ij}\) the sum of weights between two sets of vertices. Then our object function could be
where \(\overline A\) is the graph complement. Minimizing \(f\) would give the desired outcome, but we have an issue with our objective. The current function will produce lots of single vertex sets, which is not great for trying to group people together. To fix this we can “penalize” the objective function with the size of \(A_i\). Instead of the size we are going to use the volume of \(A_i\) which takes the weights into account. Let \(d_i = \sum_{j=1}^n w_{ij}\) be the degree of vertex \(i\) and \(vol(A) = \sum_{i \in A} d_i\). Now our objective is
Also define the diagonal matrix \(D \in \mathbb{R}^{n\times n}\) where \(D = \textrm{diag}(d_1,\ldots,d_n)\), \(W \in \mathbb{R}^{n\times n}\) where \(W_{ij} = w_{ij}\), and the graph laplacian \(L = D-W\).
Now we can express our minimization function as
\[\begin{aligned}
\min_{A_1,\ldots,A_k} f(A_1,\ldots,A_k) &= \min_{A_1,\ldots,A_k} \textrm{Tr} \left( H^T L H \right) \quad &\textrm{ subject to } H^TDH = I \\
&= \min_{T} \textrm{Tr} \left( T^T D^{-1/2} L D^{-1/2} T \right) \quad &\textrm{ subject to } T^T T = I
\end{aligned}\]
where we substitute \(T = D^{1/2} H\) in the last step. This is a standard trace minimization problem over a quadratic term with an identity constraint. The solution is \(T\) such that \(T\) contains the \(k\) eigenvectors of \(D^{-1/2}LD^{-1/2}\) corresponding to the \(k\) largest eigenvalues.
We can now assign vertices to clusters by using the \(k\)-means clustering algorithm on the rows of \(T\). Now vertex \(i\) is in a cluster with vertex \(j\) if rows \(i\) and \(j\) of \(T\) are assigned to the same cluster.
See an example of this process on a random graph below.
]]>Daniel NicholsCooking with Artificial Ingredients2020-10-03T00:00:00-04:002020-10-03T00:00:00-04:00https://dando18.github.io/posts/2020/03/chef-aiSometimes meandering through the labyrinth of life is monotonous and in desperate need of being spiced up. However, this just leads us back to the age old question: what spices should I use?
Many merchants traversed the globe in search of an answer (and insect larvae waste). Thanks to their trade and centuries of cooking and gastronomy research we have developed a methodic, proven system for the culinary arts. However, we are almost a year into covid-times and the world just does not make sense anymore, so why should my cooking? Thus, I present an unnecessary, over-the-top recipe generator using machine learning. And, sure, this may seem neat, but just ask your average Byzantine which is cooler: a neural network or my spice cabinet.
So how does one create recipes with machine learning? For once googling keywords was no help as ML researchers have taken to the practice of typing up their messy notes and calling them ‘X Cookbook’ where X is some generic data science jargon. Leading me, on an empty stomach, to have to actually think a little.
First, a naive approach with no domain awareness, i.e. this method will not leverage any specific knowledge about recipes except for their ordering. Recipes are sequential data: a list of unordered ingredients and ordered steps to completion (note: I am ignoring the life stories which typically precede online recipes; generating these is left as an exercise to the reader). Thus, some classification technique with memory should do a decent job. Long Short-Term Memory (LSTM) neural networks have become a standard for this type of classification task.
LSTMs, in their typical use case, take an input sequence and predict the next item in the sequence. An example could be forecasting temperature data for tomorrow given the previous 10 days. This “memory” of the previous couple days is how LSTMs differ from traditional neural networks. Rather than learning from a single static point they “remember” the previous inputs and utilize this information in their predictions. While this makes LSTMs seem more powerful than traditional networks, they still require temporal input data and struggle to learn from multi-dimensional input spaces.
Of course, existing data are needed to train the model on how to predict new samples. In our case these data are recipes. Luckily the internet is plump with well-formatted recipes making it easy to scrape them with a simple Python script1. There is also an existing dataset curated by Majumder, et al [1], but it seems to focus more on user comments than recipe contents.
Experiment
First, I will try the naive approach as it should not be too hard to implement2. I used a collection of recipes as my training data with the ingredient list and recipe steps parsed apart. In designing my dataset I faced the important decision whether to preserve the individual recipe dimension, i.e. should I keep all recipes separate in the dataset or join them all together. Keeping them separate would require either adding an extra dimension or padding/truncating recipes to all have the same length. LSTMs require significant amounts of data to train with added dimensions (and it is slow) and my recipes varied significantly in length so I did not want to pad them all to the same size. So I decided to join all the recipes together into one giant super recipe and place unique tokens in between them. Now the data looks like
As ML models require numerical values to learn I assigned each ingredient and step a unique integer and transformed the dataset using this mapping. See below for an example.
Ding! The data is ready and now we can move on to designing the learning mechanism. As I mentioned an LSTM should perform well on this task. For this approach I am just going to use a standard LSTM setup with 512 units. The network architecture is
I implemented everything in TensorFlow 2 and Python 3. You can find the source code here. Since the network is actually quite large I hoped to train it on my desktop with a GPU, but Windows decided it was a good weekend to corrupt its own partition on my hard drive. That or it was scared of my recipes. Thankfully my laptop kindly allowed me to abuse its CPU for a couple days. The network took ~45 minutes per epoch when I lowered the vocabulary size to 15,000 unique values. Both my compute limitations and lack of patience kept me from running for more than 10 epochs.
Results and Dinner
To get a random recipe from the LSTM you can feed into it an initial random ingredient and read the predicted next item. Then you append this item to your input sequence and feed it back into the network. This can be repeated until you have a sequence of desired length or in our case until the network outputs the unique ID for \(END\_STEP\). Now we can use our data mapping from before to translate the numbers into ingredients/steps and voila!
Now what is the point of any of this if I am not going to use it? So let me put my money where my mouth is… Or my mouth where my neural network is and try preparing and eating an artificially generated recipe. Besides, this whole time I have had a BuzzFeed-esque article title in my head: Letting AI Tell Me What To Eat.
I wanted to choose one of the first couple recipes that came out rather than just wait around for something that sounded good. Several of the first ones just did not make practical sense or they were a list of ingredients and just said to preheat the oven. Some of these first recipes also led me to believe my CPU was mad at me for pushing it to its limits, because it kept recommending meals with uncooked meat. But after a handful of recipes popped out I found one that seemed possible to make and, much to my surprise, actually sounded good.
Ingredients
Steps
italian sausage elbow macaroni water olive oil cooked brown rice
cook meat until brown cook pasta according to package directions turn onto a floured surface add salt and pepper to taste
I am going to interpret the turn in “turn onto a floured surface” as mixing the ingredients all together on my counter top (with flour of course) even though I do not think that is what it means.
And… It is not terrible! The concoction is in desperate need of some sauce or maybe more spices. I probably deserved just salt+pepper though for my corny opening to this post. However, it is also not bad. I made sweet italian sausage, which has a lot of flavor to it and helps the bland rice+macaroni mixture. I could do without the counter top flour though.
Improvements and Next Steps
The naive approach actually turned out pretty great considering my only two goals were to improve on a blindfolded trip to the supermarket and be less profane than Gordon Ramsey. In fact, the LSTM was still improving in terms of training accuracy and loss at 10 epochs, so I believe more computational resources could ameliorate the network’s performance. Perhaps I could sell cookbooks for money to buy better GPUs.
Yet an even better approach would be something which is aware of the relationship between recipe steps and ingredients. Consider this example recipe step: “Cut the butter into the flour”. Here butter and flour are ingredients which should be in the associated ingredients list. A smarter system should be aware of this syntax and its underlying meaning as well as learn how to generate it. A model which does this would be much more complicated than what I implemented, but it could theoretically produce more consistent results.
In its current state the algorithm is still a couple notches shy of a Michelin star. So what is the point? At first the effort was just a boneheaded attempt to entertain myself, but I think the idea has a couple promising directions in terms of applicability. One of these being a recipe auto-complete tool. Since the LSTM takes a sequence to begin, then you do not have generate an entire recipe, but can start in the middle. Maybe you have a really tasty way to cook chicken, but are looking for some ways to add to the recipe. Or maybe you need to finish off those leftovers, but you would like to spice them up a little. The possibilities are endless.
Honorable Mentions
For the time being I only cooked one recipe, but here are some of my favorites. They are not necessarily sensible recipes, but funny nonetheless.
Ingredients
Steps
chicken breasts smooth peanut butter
cool bake at 450 degrees for 15 minutes remove meat from marinade
I am really disappointed I did not end up getting this one first. I have always thought chicken breasts need a little more peanut butter. It also seems a little bit out of order.
Ingredients
Steps
milk egg yolks vanilla butter milk
set aside, and keep warm
Ah yes, my favorite blend of ingredients at room temperature.
Ingredients
Steps
powdered fruit pectin vanilla extract zucchini water
preheat oven to 325 cook transfer to a large bowl cool
Maybe an actual tasty Zucchini snack? Cannot be sure until I try it.
Ingredients
Steps
wheat bran oat bran brown sugar unsweetened applesauce vanilla instant pudding mix milk salt boneless skinless chicken breasts flour
heat oven to 350 add garlic cook for 1 minute more
I am glad the AI decided to include brown sugar to sweeten the applesauce here. Not sure where the garlic comes from though.
Ingredients
Steps
russet potato
Instructions unclear. Made vodka by mistake.
Footnotes
1After heavy use of the BeautifulSoup library for web-scraping I am now quite fond of the Adjective+Food naming convention. My next software project will be called DomineeringPickle followed by AdventurousBaguette.↩
2The only thing naive about this approach is me saying it would be easy to implement.↩
]]>Daniel NicholsThe Digital Librarian2020-09-03T00:00:00-04:002020-09-03T00:00:00-04:00https://dando18.github.io/posts/2020/09/digital-librarian-part-0I love scouring old book stores for cool finds and oddities, but I often worry about missing a diamond in the rough. Unfortunately, there is not enough time to dive into every book in a shop and if we cannot judge a book by its cover, then how are we supposed to judge them by only the spine! As a true computer scientist I decided to build an over-the-top tool to help me out.
After some lengthy research into computer vision I built an app, which allows you to point your phone camera at a bookshelf and see information about each one of the books in front of you. Unfortunately, text-detection and OCR within a scene are non-trivial tasks and I was only able to get around 70% accuracy rate on identifying books. But this number is also skewed by the fact that a lot of old books in used book stores are crumbly and hard to read with even a human eye. Improving this accuracy rate is saved for a later date. The tool also turns out to be great for cataloging your own bookshelves at home!
In this image we have 10 books lined up next to each other. Simpler images can often be segmented (split into objects) by finding edges and then finding contours. This simpler approach, unfortunately, does not work for bookshelves very well as the books are “connected” making it hard to find a good contour. So we need something a little more clever.
Picking Books
The first thing we need to do is identify individual books within the image and divide them out. To do this I am going to use a technique called the Hough transform to identify lines within the image.
However, we need some preprocessing steps before using the Hough transform. First, we need the edges of the image. To do this we must first convert the image from 3 channels (Red, Green, Blue) to 1 (Grayscale). Once in grayscale Canny edge detection can pull out the edges [1].
Canny edge detection works by first applying the Sobel operator to get gradients in the \(x\) and \(y\) directions, \(G_x\) and \(G_y\). Then, for each pixel we can use the below equations to calculate the edge gradient and direction.
Now we “suppress non-maximums”. This is fancy speak for looking at each pixel and determining if it is a local maximum in the direction perpendicular to the edge. The calculated gradients give us the perpendicular edge.
Finally, we examine each edge pixel from above and check whether it is really an edge using low and high thresholds. Below the low threshold and it is not an edge. Above the threshold and it is definitely an edge. In the middle and it is only an edge it is connected to another above or in-the-middle pixel.
After these steps we should have pretty good edges for our image. This page has a much better explanation of Canny image detection with pictures. See the below image for the books with Canny image detection.
Bookshelf Image with Canny Edge Detection
Now we need to split up the books somehow. This is actually quite difficult, but experimentally I have found that the Hough Transform performs reasonably well at this task. The Hough transform works over several different kinds of parametric spaces, but for this example I used it to find lines within the image.
Currently our image, while showing edges, is still just a bunch of pixels. There is no geometric understanding of “shape”. The Hough transform allows us to find parameterized lines within the image giving an understanding of the geometry. Lines are fairly simple as they can be parameterized by \(y = \theta_1 x_1 + \theta_0\). However, to allow for vertical lines we parameterize by \(r = x\cos\theta + y\sin\theta\).
Now for every point in the image \((x_n, y_n)\) we have a function \(r_{x_k,y_k} : [0, 2\pi) \mapsto \mathbb{R}^+\) defined by \(r_{x_n,y_n}(\theta) = x_n\cos\theta + y_n\sin\theta\). Now we define the set \(\mathcal{H}_{x_n, y_n}\)
\[\mathcal{H}_{x_n, y_n} = \{ (x_k, y_k) \mid r_{x_n,y_n}(\theta) = r_{x_k,y_k}(\theta) \land k \ne n \land (x,y) \in Image \}\]
\(\mathcal{H}_{x_n, y_n}\) is the set of all points whose curve intersects the curve of \((x_n, y_n)\). Consider the set \(\mathcal{H} = \{\mathcal{H}_{(x_n,y_n)} \mid (x,y) \in Image \}\) of all intersection points. Then we can define lines as
where \(t\) is some threshold for the number of intersections to qualify as a line. The process for actually computing \(Lines\) looks somewhat different, but still involves finding sets of intersections for every point. The Hough lines for our test book image, pictured below, actually look quite good. There are probably better techniques for segmenting books, but that is left as work for a future date.
Hough Lines
Finally, we have subdivided our books using lines, but we need to “crop” out each book spine for text processing. This can be done by identifying contours within the lines from the Hough transform and masking out each contour region.
To identify contours (geometric shapes within the image) we can use the algorithm by Suzuki, et. al. [2], which is quite complicated, but also conveniently implemented in the open-source project OpenCV. To find the contours I use the Hough lines placed on a white background, so no other image details are identified as contours. Below the contours for our test image are shown in green.
Book Contours in Green
Now for each contour we can mask it on top of the original image to crop out the contents. This will give us a small image for each spine, which we can use for identifying the book. For example, the spine for “The Narrow Road to the Deep North” is shone cropped out in the figure below.
TADA! We have successfully cropped out each book spine in the image.
Judging a Book By Its Spine: Text Detection
The temptation here is to just pipe each image into an OCR algorithm/program and try to get the text. However, as you can notice from our test image: a lot of books have non-standard text alignments. Some have the entire text rotated 90 degrees, while others might have standard text vertically down the spine. We need a way to first identify text within the image and determine its location and orientation.
Identifying possible text within a scene is possible with the EAST neural network developed by Zhou, et. al. [3]. EAST is a deep neural network, which can identify and locate probable text within an image. It has its limitations, but it works quite well for our task. Additionally, network inference with this model can be done quite quickly: ~13 FPS as cited by the paper authors. To the right is the EAST network layers as depicted in the paper.
Once the text has been found we can mask and crop it out like before to feed into an OCR algorithm. I did not delve too far into OCR algorithms, but rather used the LSTM networks in Tesseract OCR for image-to-text. Below is the text found by EAST on “The Narrow Road to the Deep North” spine.
Again, TADA! The OCR pulls out the text [“The”, “Narrow”, “Road”, “Deep”, “North”, “Richard”, “Flanagan”, “Knopf”]. This text, along with the coordinate data, is enough to query a database or google for more information about the book.
Improvements
After some toying around with these computer vision algorithms I believe there are 2 major improvements, which would drastically help the overall accuracy. First, using a different image segmentation algorithm. Segmenting the books using Hough lines works well, but there are much better, more generalizable methods. I looked into RCNN-based approaches, but they all seemed like overkill and they do not work in realtime. More research is needed to find a better segmentation algorithm.
Second, up-scaling the text and using a super-resolution network could help the OCR, which struggled a lot with small font sizes on some books. There has been some recent work by Wang, et. al. on super-resolution scaling for text, which could greatly improve the accuracy of the OCR pipeline stage [4, 5]. Getting this up-and-running, however, seems to be non-trivial.
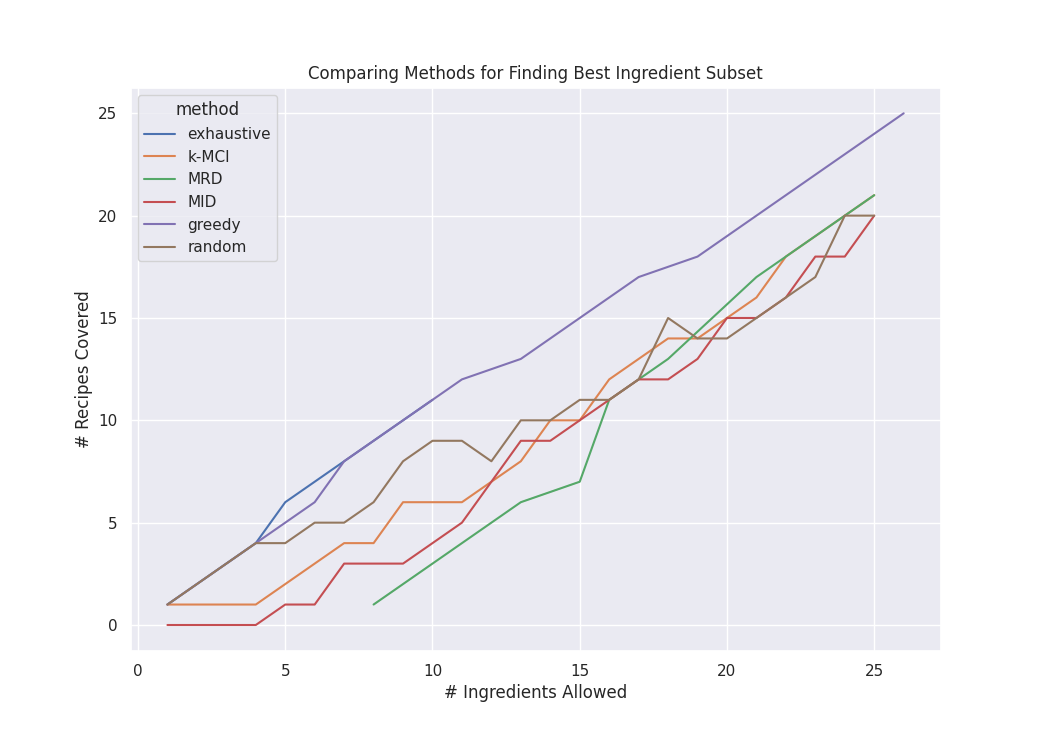
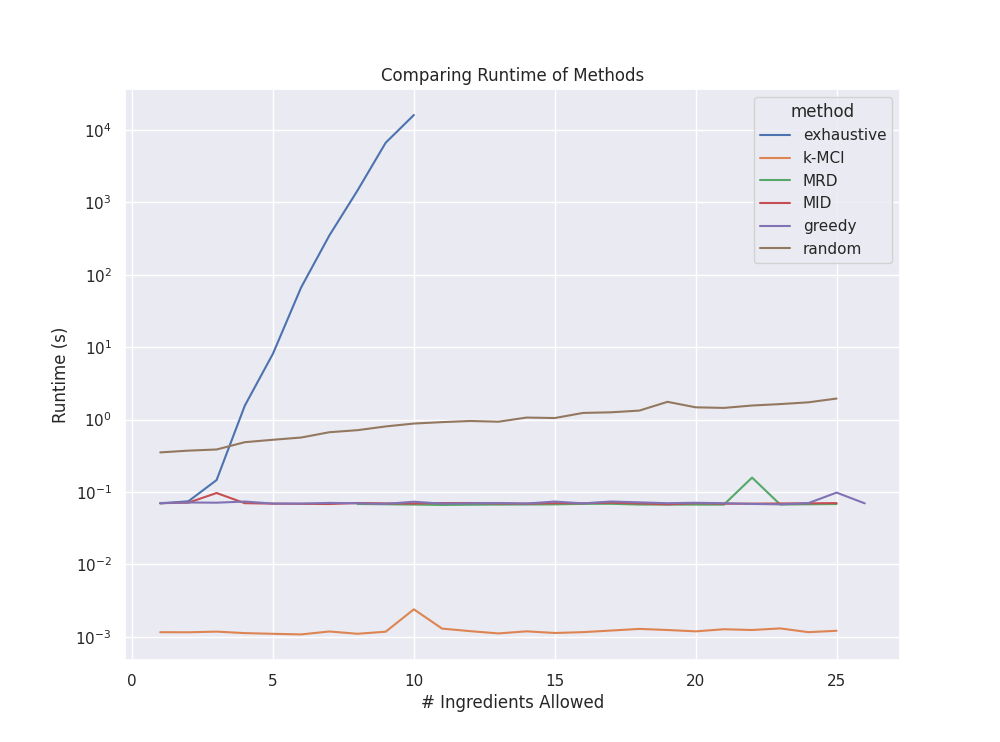













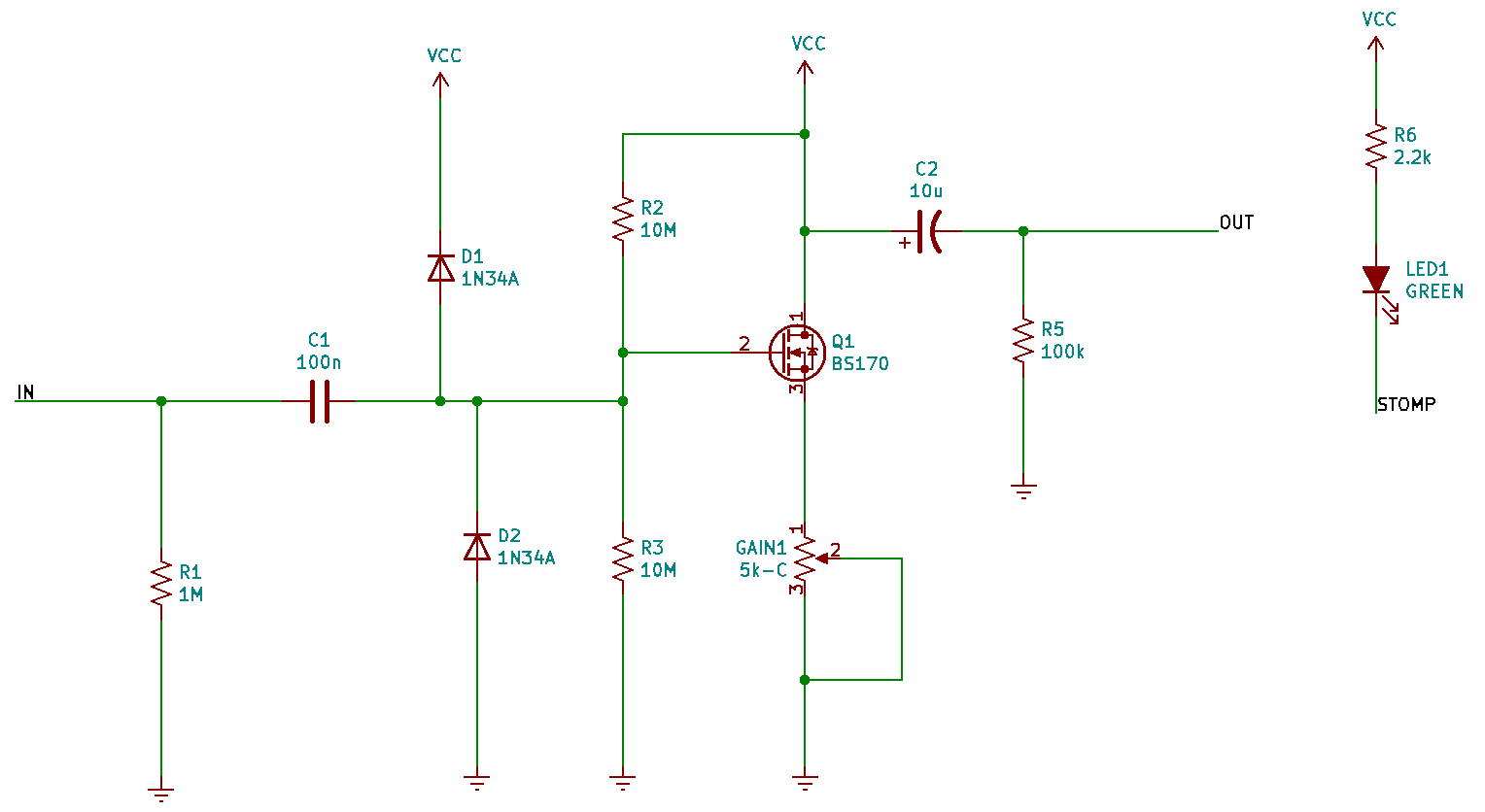












 EAST is a deep neural network, which can identify and locate probable text within an image. It has its limitations, but it works quite well for our task. Additionally, network inference with this model can be done quite quickly: ~13 FPS as cited by the paper authors. To the right is the EAST network layers as depicted in the paper.
EAST is a deep neural network, which can identify and locate probable text within an image. It has its limitations, but it works quite well for our task. Additionally, network inference with this model can be done quite quickly: ~13 FPS as cited by the paper authors. To the right is the EAST network layers as depicted in the paper.